Evolve your own beats -- automatically generating music via algorithms
Update: you can find the next post in this series here.
I recently went to an excellent music meetup where people spoke about the intersection of music and technology. One speaker in particular talked about how music is now being generated by computer.
Music has always fascinated me. It can make us feel emotions in a way few media can. Sadly, I have always been unable to play an instrument well. Generating music by computer lets me leverage one of my strengths, computer programming (which, contrary to popular belief, can be extremely creative), in order to make music. Although I’m not exactly sure how people are doing it now (explicit parsing rules?), I thought of a way to do it algorithmically (because everything is more fun with algorithms, right?)
I opted to pursue a strategy that “evolves” music out of other pieces of music. I chose this strategy in order to emphasize the process. Seeing a track take shape is very exciting, and you can go back to its history and experience each of the tracks that took part in its creation.
I’m going to broadly outline the keys to my strategy below. You might think that a lot of my points are crazy, so bear with me for a while(at least until I can prove them out later):
- We can easily acquire music that is already categorized (ie labelled as classical/techno/electronic, etc)
- We can teach a computer to categorize new music automatically.
- Teaching a computer to categorize music automatically will give us a musical quality assessment tool (patent pending on the MQAT!)
- Once we have an assessment tool, we can generate music, and then use the assessment tool to see if it is any good
- Profit?
One important thing to note is that while the music itself is automatically generated, the building blocks of the final song are extracted from existing songs and mixed together. So don’t worry about this replacing humans anytime. The key to the algorithm is actually finding readily available, free music, and I would sincerely like to thank last.fm and the wonderful artists who put up their music up in their free downloads section. I am not sure how much my algorithm has obfuscated the original sounds of the music, but if anyone recognizes theirs, I would love to hear from them.
So, how did you do it?
I used some of the knowledge that I had built up from doing audio analysis on the Simpsons to attempt music generation. If you have time, I recommend reading that entry.
The first thing I did was write a web spider to automatically grab links to free music from the last.fm free music section. I was able to download 500 tracks using this crawler. Half of the tracks were classical music, and half electronic.
Unfortunately, these tracks were in .mp3 format. Mp3 is a proprietary codec, which makes it harder to decode, process, and work with. I was able to get around this by converting the .mp3 tracks to ogg, which is a free audio format, using the tools mpg123 and oggenc.
I was then able to extract audio features from these tracks. Audio features are numbers that describe the sound in a song. Sound is just a wave. We can measure how instense that wave is at various points in time, which gives us a sequence of numbers that describe that sound. We can later use those numbers to replay a song, which is what happens in modern music players.
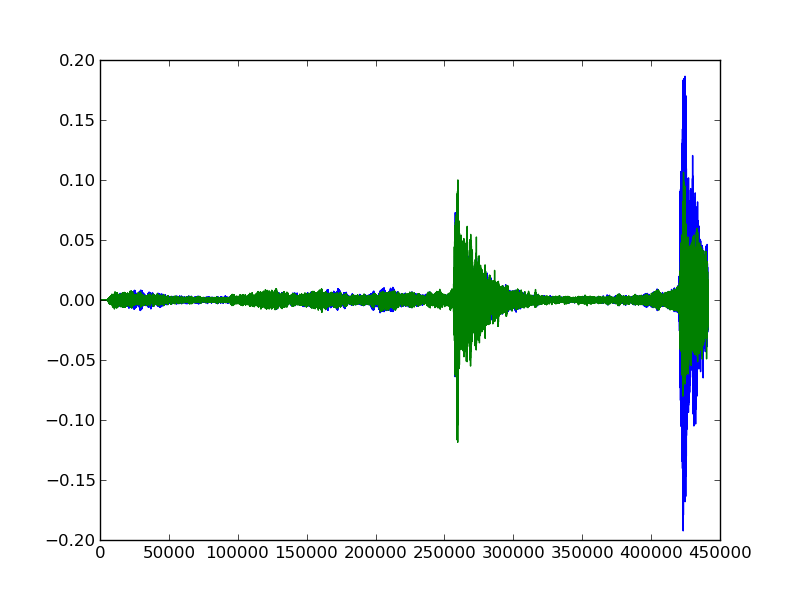
Here are the sound waves in the first 10 seconds of a classical track:
 And here are the sound waves in the first 10 seconds of an electronic track:
And here are the sound waves in the first 10 seconds of an electronic track:
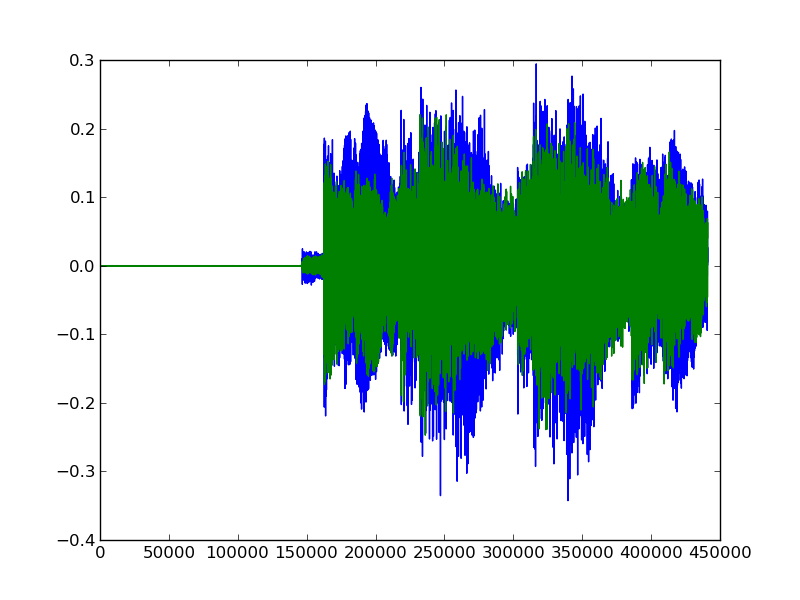 One of the lines is the left channel audio, and one is the right. It doesn’t matter overly much which is which. Let’s say that green is right. We can quickly see that the second track has more intense peaks, and appears to have higher energy when compared with the classical track. Using our knowledge of classical music vs electronic music, this makes sense. Just like we can look at the two graphs and understand that they are different, so can a computer.
One of the lines is the left channel audio, and one is the right. It doesn’t matter overly much which is which. Let’s say that green is right. We can quickly see that the second track has more intense peaks, and appears to have higher energy when compared with the classical track. Using our knowledge of classical music vs electronic music, this makes sense. Just like we can look at the two graphs and understand that they are different, so can a computer.
For example, when we read the classical track in, the first 10 audio samples produce the following:
And the first 10 audio samples from the second track produce:
These numbers describe how the sound waves look. The numbers on the left are the left audio track, and the numbers on the right are the right audio track. Each sound is sampled 44100 times per second, so one second of audio will result in a 44100x2 matrix. The 10x2 matrices that we see above represent approximately .00022 seconds of audio.
Let’s say that someone asked you to look at the numbers from a 1 minute audio sample and summarize what made it good or bad. There will be 2646000 numbers in each audio track, and it is almost impossible to make any meaningful decisions when swamped with so much information. It is the same way with a learning algorithm, so we extract audio features to reduce the dimensionality and make it easier for the computer to understand what is going on.
We calculate several features, including changes in peak intensity throughout the track, zero crossing rate, and mel frequency cepstrum coefficients. All of the features can be found here. These features describe each of our sound tracks using only 319 numbers instead of 2646000+.
Training the algorithm
Once we have our features for each of our tracks, we can go ahead and create our musical quality assessment tool (MQAT). Our MQAT will decide if a track is classical or electronic music. We will have to assign the label of “0” to one type of music, and “1” to the other. I gave classical a 1, and electronic a 0, which is not a reflection of my own musical taste.
With the features and labels, it is possible to train an algorithm that will make up the heart of the MQAT. The algorithm can tell if an input track is classical or electronic. More crucially, it will give you a decimal number between 0 and 1 that indicates how classical or how electronic a track is. We can take this number, and detect the quality of music by how close it is to 0 or 1. If a piece of music is a classified close to a 0 or a 1, its audio signature is likely to match our existing tracks, which will make it more likely to be good than if it doesn’t.
Splicing/Remixing
Once we have a musical quality assessment tool, we can splice new tracks into our existing tracks to make remixes. Here is roughly how splicing works:
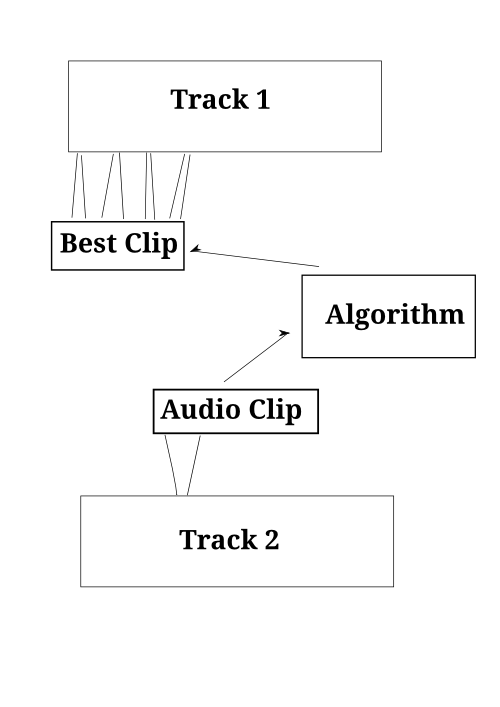 So, we pull a randomly selected short audio clip out of a randomly selected track (Track 2). We then use the quality assessor (Algorithm) to see if it is good (if it close to 0 or 1, as we are defining things that are pure examples as “good”). We do this a few times, and take the “best” audio clip (Best Clip), and insert it into several evenly spaced places in the original track (Track 1).
So, we pull a randomly selected short audio clip out of a randomly selected track (Track 2). We then use the quality assessor (Algorithm) to see if it is good (if it close to 0 or 1, as we are defining things that are pure examples as “good”). We do this a few times, and take the “best” audio clip (Best Clip), and insert it into several evenly spaced places in the original track (Track 1).
This splicing procedure is repeated until the original song (the song that clips are being spliced into, Track 1) gets a high quality rating and is different from all of the other tracks (measured through euclidean distance), or until the specified number of splices is done. The high quality rating is important, because we want the new song to sound decent. The distance is also important; we don’t just want to make a derivative of one of our existing songs, we want to make something a bit original (although I can’t exactly quantify how original).
Through this splicing, we end up with a very different track from the original; one that could have insertions from dozens of other songs, making a very intricate remix (indeed, in almost all cases, there are no traces of the original song).
Looking at a single song
Once we have a way to splice, we can perform the splicing for each of our input songs.
Once we get our first remixed song, we can look at the first 10 seconds:
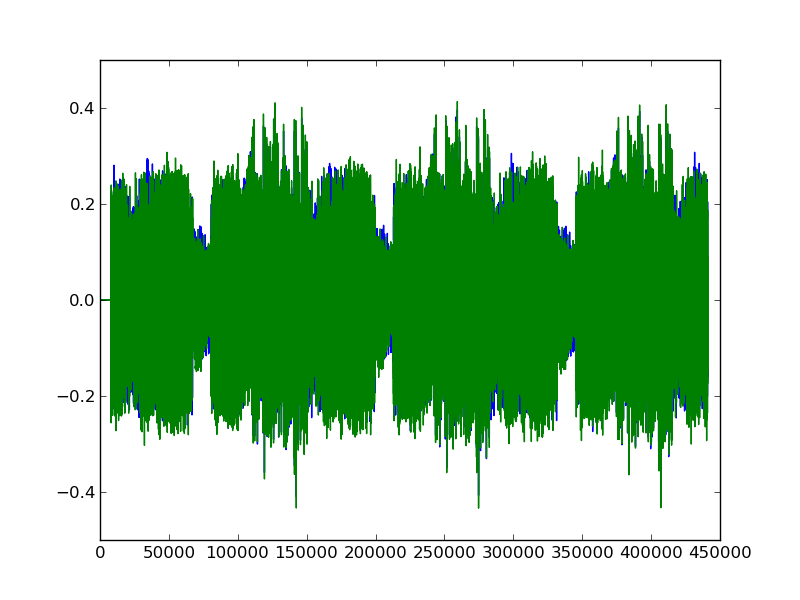 We can see that its audio signature appears to be more towards the electronic side, rather than the classical side.
We can see that its audio signature appears to be more towards the electronic side, rather than the classical side.
The song_index is the number of the original song in my song database. iteration is which iteration the algorithm is on (the algorithm will iterate a maximum of 100 times, but can stop sooner if it makes a good song). At each iteration, a best clip will be selected (as per the diagram above), and splicing will be performed. quality is the quality of the track from 0 to 1. 0 means the track is electronic, and 1 means that it is classical, and numbers in between indicate various degrees of electronic-ness and classical-ness. The algorithm considers a created song to be good if its quality is close to 0 or close to 1. distance is how similar the created song is to the existing songs in the database. The algorithm will try to create a high quality song that is not similar to the songs in the database. splice_song_index is the index of the the song that is being spliced into the created song at the specified iteration. splice_song is the name of the spliced song.
In the above history, we start at iteration -1, which is the original song. The first splice song, 25D1%2581%25D1%258F.ogg, is then chosen to be spliced in. Best clips are selected and spliced into the original track 10 times, after which a new song is picked on iteration 10. The quality is also computed at iteration 10, and we can see that the song has moved from classical to electronic quite dramatically. We continue this process until iteration 70, when the quality is very high, and the distance between this track and all the others is also high, making this a good song to save.
It is pretty amazing to see music take shape, and having the history helps us better understand and experience the evolution of the track.
Looking at all songs
Once we have generated a few tracks, we can reduce the features in them to 2 instead of 319 using singular value decomposition. We can also do this for the original songs in our database. This projects the values into two dimensions, which allows us to plot them:
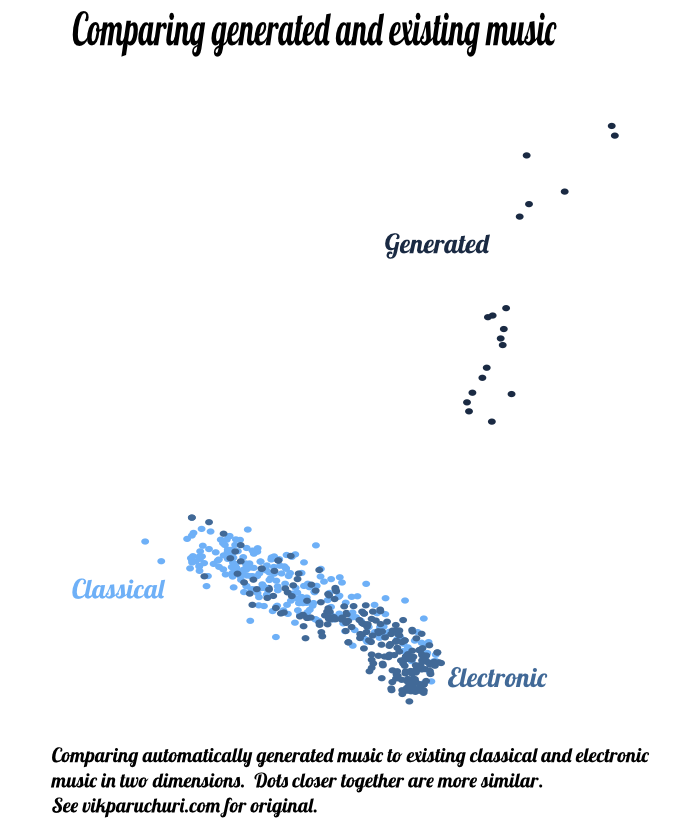 We are visualizing 522 songs, 22 of which are generated songs. The dots closer together are more similar. We can see that classical and electronic tend to be grouped together, with some overlap.
We are visualizing 522 songs, 22 of which are generated songs. The dots closer together are more similar. We can see that classical and electronic tend to be grouped together, with some overlap.
What is very surprising is that all of our generated tracks are distinct from classical and electronic music, but they are all very similar to each other. We have evolved an entirely new genre of music out of classical and electronic! (or perhaps two different genres, given the clustering). Does anyone want to name this?
If we altered some of the parameters of our algorithm that control splicing and timing, we may be able to create more genres of music.
Final Words/Improvements
This was an interesting project to work on, particularly because there really isn’t a “right” answer with music (at least until humans listen to something and decide if they like it or not). I can’t stress how much of a debt I owe to the human creators who made the source music. This algorithm is less about usurping the existing creative process than trying to define a new and distinct creative process.
You can find all the code for everything I have described so far here.
The music made here isn’t the best music you will ever hear. Here are some ways that I can think of to make this better:
- Make transitions between segments more smooth.
- Train an additional algorithm to recognize notes that can be combined well (or just use a simple heuristic to see if one can blend into another)
- Use more input tracks for training
- Try this with other types of music, like rock or hip hop
- Try to filter out specific bands, such as vocals, and combine them
- Splice in irregular patterns
- Add in operations other than splicing
- Try to optimize the fitness of the output track (more of a genetic algorithm approach)
I will probably fiddle with the algorithm and try some of these in the next few days, if I have time.
I hope you enjoyed this, and would love to hear your thoughts.
